

A distributed cache is one that spans multiple nodes. Data is stored (and possibly replicated) across the nodes, providing certain guarantees about availability and consistency. If you’re interested in learning more real-life use cases, read the excellent Dynamo paper from AWS - the paper for distributed KV-stores.
Simple GenServer
GenServer, an OTP generic behaviour for building request-response interactions, will be our starting point. It’s a single-threaded server with a message box of incoming requests. Our data will be stored in a plain map, and we’ll define just the operations for getting and setting a key-value pair:
defmodule Storage do
use GenServer
def start_link(opts), do: GenServer.start_link(__MODULE__, opts, name: __MODULE__)
def get(key) do
GenServer.call(__MODULE__, {:get, key})
end
def put(key, value) do
GenServer.cast(__MODULE__, {:put, key, value})
end
def all, do: GenServer.call(__MODULE__, :all)
# Callbacks
@impl true
def init(_state), do: {:ok, Map.new()}
@impl true
def handle_cast({:put, key, value}, state) do
{:noreply, Map.put(state, key, value)}
end
@impl true
def handle_call({:get, key}, _from, state) do
{:reply, Map.get(state, key), state}
end
@impl true
def handle_call(:all, _from, state) do
{:reply, Map.to_list(state), state}
end
end
This works reasonably well, until the process dies an untimely death - then our state is gone. Also, frequent accesses to a single process would quickly make it a contended resource and a single point of failure. We could perhaps spawn multiple such processes, and distribute the load among them? And what if those processes could potentially live on different server nodes than the one calling it? This requires us to answer two questions:
- How do we distribute access across multiple machines?
- How do we ensure data remains consistent across those machines?
Distributed Erlang
Erlang has a built-in support for distributed computing. We can start BEAM instances (referred to as node) on multiple machines and connect them together to form a cluster. Processes on one node will be able to send messages, link, and monitor each other—even across node boundaries—when using process identifiers (pids).
The daemon facilitating node discovery and connections is called epmd, which acts like a small DNS server for the nodes. It listens on a well-known port and coordinates discovery process:
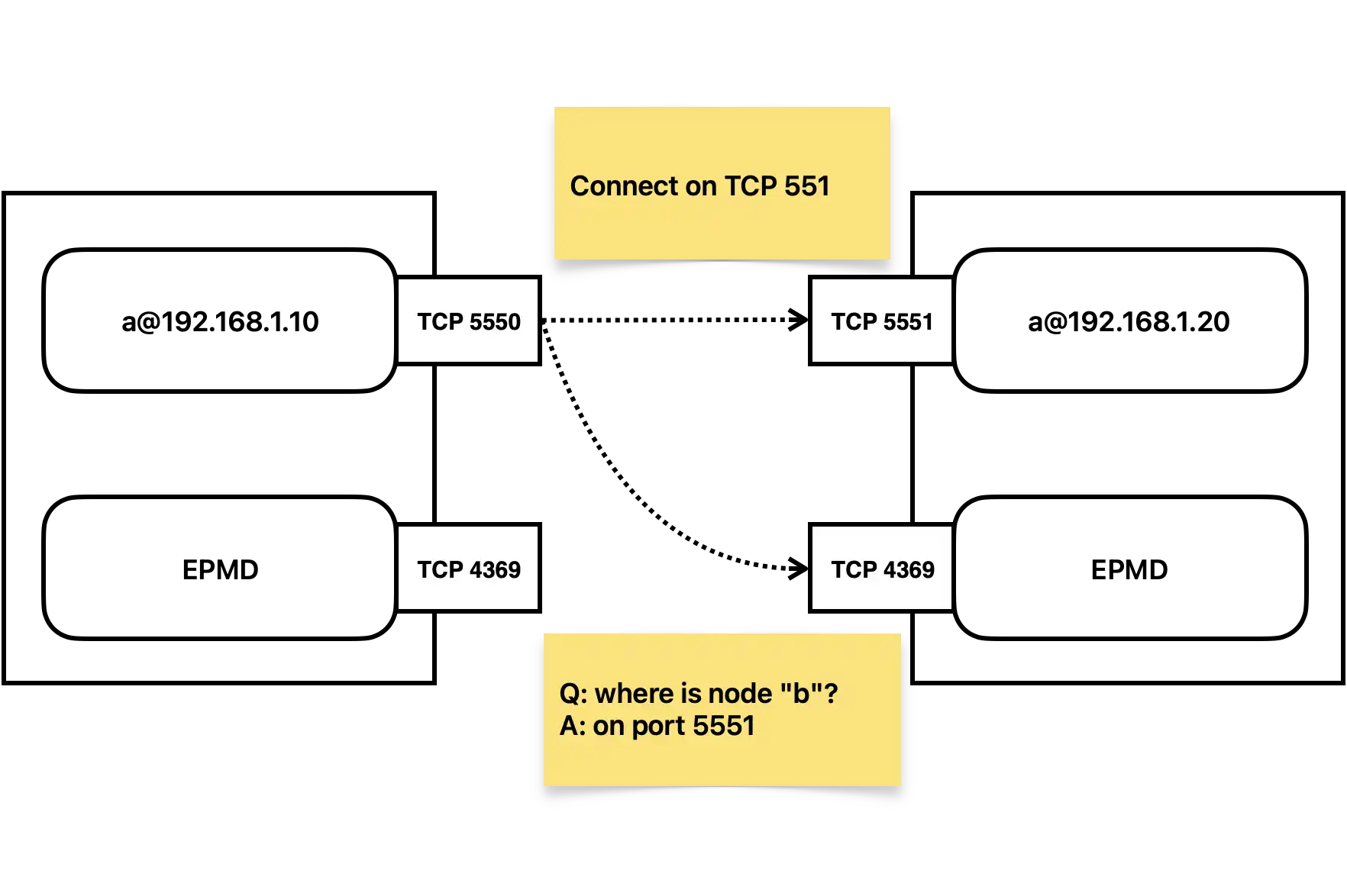
Erlang will form a fully-connected mesh network of all connected nodes, one we will use to distribute our storage. Naturally, production systems use automated node discovery provided by libcluster, whose configurable strategies allow Elixir to form networks in environments like Kubernetes, ECS Fargate, EC2 etc. We assume we use such mechanism to connect our nodes in the following section.
Connecting Nodes
To try this out on your local machine, you’ll need to start two BEAM instances in separate terminal tabs. First, ensure Elixir is installed, then start iex with a special flag to assign a name to each node:
iex --name a@127.0.0.1
Then, in a second terminal/tab:
iex --name b@127.0.0.1
Now, in either tab, call Node.list() and verify that it returns an empty list, and then Node.ping(:"a@127.0.0.1") from node b. You should get a :pong response. Now, try typing in Node.list() again and verify that it shows [:"a@127.0.0.1"]. That’s it, you’ve created your first cluster!
We can also connect the nodes together with Node.connect/1:
# From node "a@127.0.0.1"
iex(1)> Node.connect(:"b@127.0.0.1")
iex(1)> Node.list()
[:"b@127.0.0.1"]
Distributing Data
Our little cache has the simplest possible access pattern - value is uniquely identified by a key. Assuming we have N processes in our cluster, we can deterministically map each key to a process index by a modulo hash:
let node = hash(key) % N;
We would then route the request for key to the given node, which would be guaranteed to hold this value. This assumes a static world - nodes can’t be added or removed on demand. If they were, we would have to reshuffle the entire keyspace to ensure the new mapping with different N stays consistent.
This is not ideal in real-world scenarios. Our goal is to distribute data evenly across servers, ensuring each receives roughly the same load. Ideally, we’d want keys to map to nodes uniformly at random, just like in an ordinary hash table. Let’s take a look at rendezvous hashing, an algorithm designed to solve this problem.
Rendezvous hashing offers an elegant distributed hash table. Rather than pick a single server, each key receives a randomly sorted list of nodes and chooses the first node from the list. Here’s how nodes are assigned to keys:
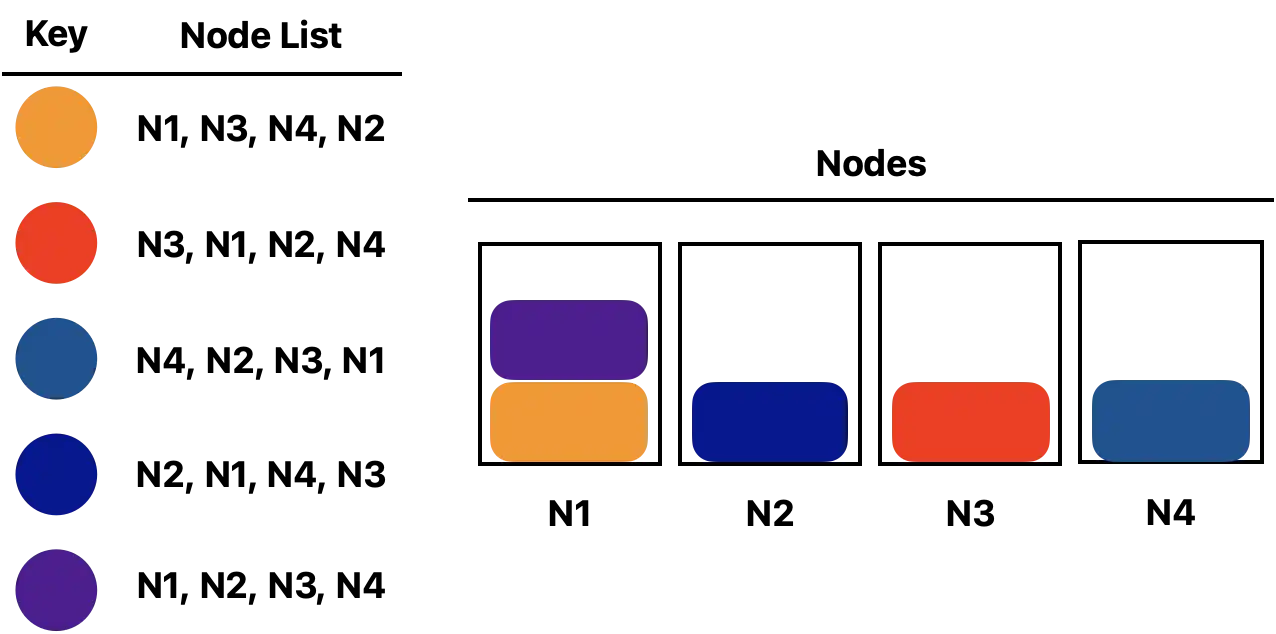
If our first choice for a node goes offline, we simply move the key to the second node in the list (which becomes our new first choice). It is easy to see that we only need to move the keys that were previously managed by the node that went offline. The rest of the keys do not need to move, since they are still managed by their first choice. For example, if we were to delete node N1 in the example, the items in N1 would move to their new first choices: N2 and N3. None of the other items have to move though, since N2 wasn’t their first choice.
How do we generate a randomly sorted node list for each key? We can simply concatenate the key with the node and hash the result, then sort the nodes by that value in descending order:
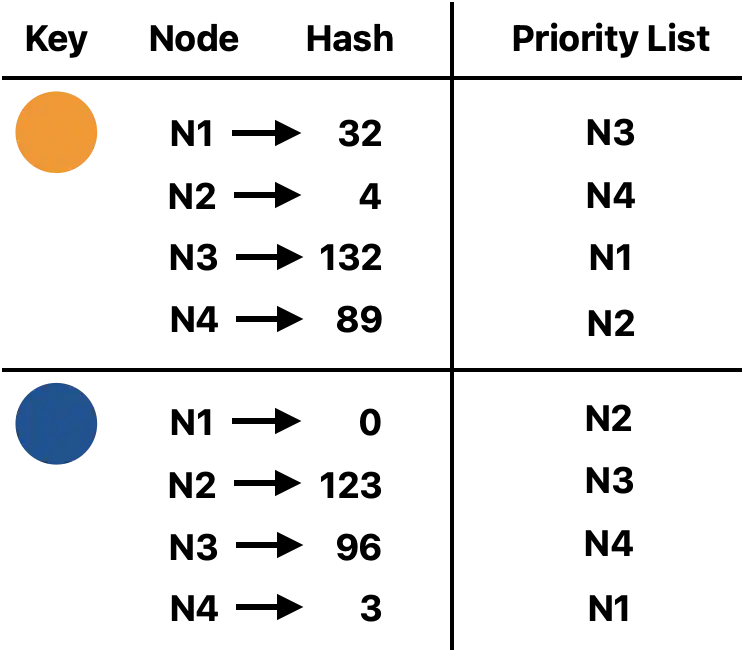
Okay! Now let’s leverage OTP to implement the above algorithm. We will employ a GenServer to maintain an up-to-date list of nodes in the cluster, and provide a priority list for a given key:
defmodule Distribution do
use GenServer
def start_link(opts), do: GenServer.start_link(__MODULE__, opts, name: __MODULE__)
def get_priority_list(key) do
GenServer.call(__MODULE__, {:get_priority_list, key})
end
# Callbacks
@impl true
def init(_opts) do
:net_kernel.monitor_nodes(true)
{:ok, MapSet.new([Node.self() | Node.list()])}
end
@impl true
def handle_call({:get_priority_list, key}, _from, nodes) do
list =
nodes
|> MapSet.to_list()
|> Enum.map(fn node -> {node, :erlang.phash2({key, node})} end)
|> Enum.sort_by(fn {_node, weight} -> weight end, :desc)
|> Enum.map(fn {node, _weight} -> node end)
{:reply, list, nodes}
end
@impl true
def handle_info({:nodeup, node}, state) do
{:noreply, MapSet.put(state, node)}
end
@impl true
def handle_info({:nodedown, node}, state) do
{:noreply, MapSet.delete(state, node)}
end
end
The :net_kernel.monitor_nodes/1 function allows us to monitor node connections and disconnections, which we manage in our process state. The priority list is sorted by the hash of the {key, node} tuple. We’re using :erlang.phash2/1, a fast built-in hash function mapping Erlang terms to range 0..2^27-1, which should guarantee uniform key assignment across nodes.
Routing Requests
Now that we have a way to determine which node should handle a request, we tweak the access pattern of the cache to route requests to the node responsible for the key. Calling a GenServer on a remote node is as simple as passing the {__MODULE__, node} tuple instead of __MODULE__. Should the first choice node in the priority list fail, we try the subsequent ones, up to @max_nodes in total. To handle network failures, we catch the :timeout and :exit errors and log them accordingly.
defmodule Storage do
use GenServer
require Logger
@max_nodes 3
def start_link(opts), do: GenServer.start_link(__MODULE__, opts, name: __MODULE__)
def get(key) do
key
|> Distribution.get_priority_list()
|> Enum.take(@max_nodes)
|> Enum.reduce_while(nil, fn node, acc ->
try do
{:halt, GenServer.call({__MODULE__, node}, {:get, key})}
catch
:exit, {:timeout, _} ->
Logger.warning("Timeout when fetching key #{key} from #{node}")
{:cont, acc}
:exit, reason ->
Logger.error("Failed to fetch key #{key} from #{node}: #{inspect(reason)}")
{:cont, acc}
end
end)
end
def put(key, value) do
node =
key
|> Distribution.get_priority_list()
|> List.first()
GenServer.cast({__MODULE__, node}, {:put, key, value})
end
# Callbacks
# ...
end
As for storing data, for now we choose to only put the key-value pair on the first node in the priority list. We might also replicate it across the remaining nodes up to @max_nodes if we prioritize higher availability.
All right, but what if a node goes down, or a new one is added? The priority list will surely change, and the new first choice node may not yet have the key. If we were building a database, we would need to guarantee more robust behaviour - we’ll explore this in the next section.
However, this is not a really problem for cache systems. In a cache system, users access data through fast, local servers that have shared access to a slow central data storage repository. When a user requests data from the system, we query the cache to see whether a local copy is available. If the cache doesn’t have a copy, we fetch the data from the upstream and cache it for next time.
Node Additions and Removals
When a node is added or removed, the priority lists for keys will change. If we were to make our cache robust, we can:
- Move the data from a first choice node that is shutting down to the second choice node.
- Move the data from a previously second choice node to the first choice node when a new node is added.
We’ll cover the first improvement in this section. Elixir allows us to trap exits of processes, which is what we will use to gracefully move the data on node shutdown. We’ll employ a GenServer that will fetch all local key-value pairs, filter those for whom the current node is the first choice, and then send them to the second choice node. Naturally, this is a naive and not very performant solution, it serves as proof of concept:
defmodule ShutdownHandler do
use GenServer
def start_link(opts), do: GenServer.start_link(__MODULE__, opts, name: __MODULE__)
@impl true
def init(_opts) do
Process.flag(:trap_exit, true)
{:ok, []}
end
@impl true
def terminate(_reason, _state) do
node = Node.self()
Cache.all()
|> Enum.map(fn {key, value} -> {key, value, Distribution.get_priority_list(key)} end)
|> Enum.filter(fn
{_key, _value, [^node, _second | _]} -> true
_ -> false
end)
|> Enum.each(fn {key, value, [^node, second | _]} ->
GenServer.cast({Storage, second}, {:put, key, value})
end)
:ok
end
end
Supervising the Cache
We can now host the moving parts under a supervisor, which will ensure that they are restarted in case of failure. Note that the shutdown handler is started last and will be the first to be terminated - this ensures we can gracefully shut down while the distribution and storage are still running.
defmodule Cache do
use Supervisor
def start_link(opts), do: Supervisor.start_link(__MODULE__, opts, name: __MODULE__)
@impl true
def init(_opts) do
children = [
Storage,
Distribution,
ShutdownHandler
]
Supervisor.init(children, strategy: :one_for_one)
end
defdelegate get(key), to: Storage
defdelegate put(key, value), to: Storage
defdelegate all(), to: Storage
end
We can now place the cache in an application supervision tree and reap the benefits of distributed Erlang out of the box. Note, a clustering strategy other than manual node connection is recommended for production use.
Conclusions
Elixir/OTP offers a lot for quickly prototyping web applications, however it truly shines when it comes to building distributed systems. Our toy example is already functional, and with a proper LRU eviction policy, it could be used in production.
The rendezvous hashing is one of the approaches to load balancing, the other prominent one being consistent hashing, where the hash function range is represented as a wrapping ring, and segmented between the nodes. When a new node is added, it takes over a segment of the ring, possibly changing the ownership of some keys:
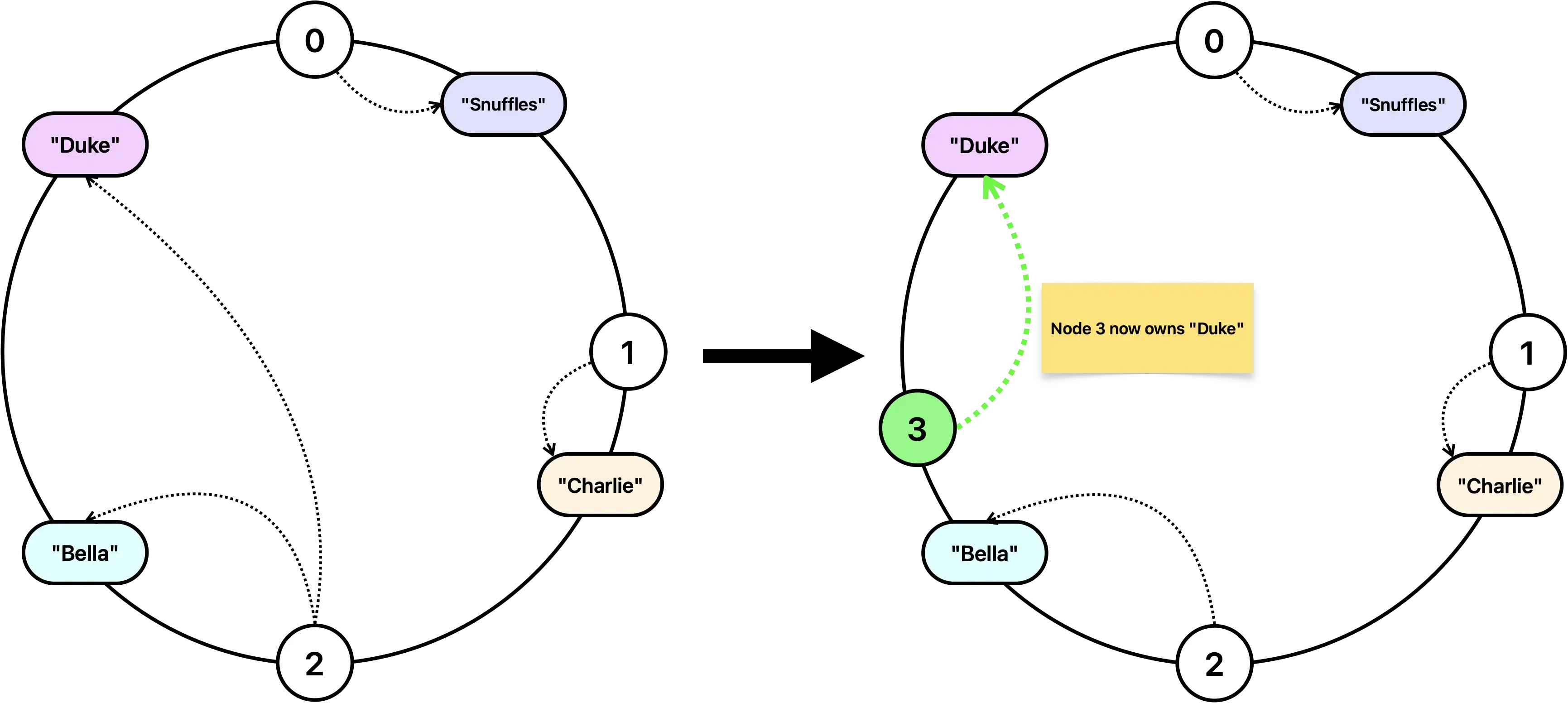
I’ve chosen to go with rendezvous hashing as it’s simpler to implement and conceptualize. Both techniques perform reasonably well in small to medium-sized caches.
It seems Cachex offers a clustered mode, I am yet to try it out.


{kind=link}