

Message processing is ubiqutous in many modern applications - whether it’s motivated by an eventually consistent architecture, ingestion of events from external systems or IoT devices.
Much like with request-based traffic, our application needs to be able to scale with the volume of incoming messages. As the amount of work that needs to be done grows, there is an increasing chance of hitting a limit of our CPU/memory resources. Horizontal scaling is one solution, especially if available out of the box on Kubernetes or other PaaS offering.
Still, we want to be able to utilize existing resources as good as possible, and gracefully limit our processing rate to avoid overwhelming the system. Before we get into it, we’ll explain what backpressure is, and how it enables us to build data processing pipelines.
What is backpressure?
Backpressure is a concept of limiting the work done by the consumer of some data stream to what it can handle at a given time. Essentially, it’s a way of telling the upstream producer “hey, my capacity is X messages at the moment, give me no more than that”. This allows us to avoid overwhelming the system with too many messages at once, which can lead to performance degradation or even crashes.
Introducing GenStage
GenStage is an Elixir library providing the core abstraction of a data processing stage, and an OTP behavior for modeling stages of data processing pipelines. It allows us to build concurrent and scalable systems that can handle backpressure effectively. The topology of a pipeline is completely up to the user, and in a moment we’ll see how different “kinds” of stages can be used to build a well-defined event ingestion pipeline. Example:

Although events move between stages from left to right on our diagram, the flow of events is controlled from the opposite direction. This is because the demand for more events travels from right to left. The next stage tells the previous how many events it can handle at a given time. This is what backpressure is about. This figure shows how it works:
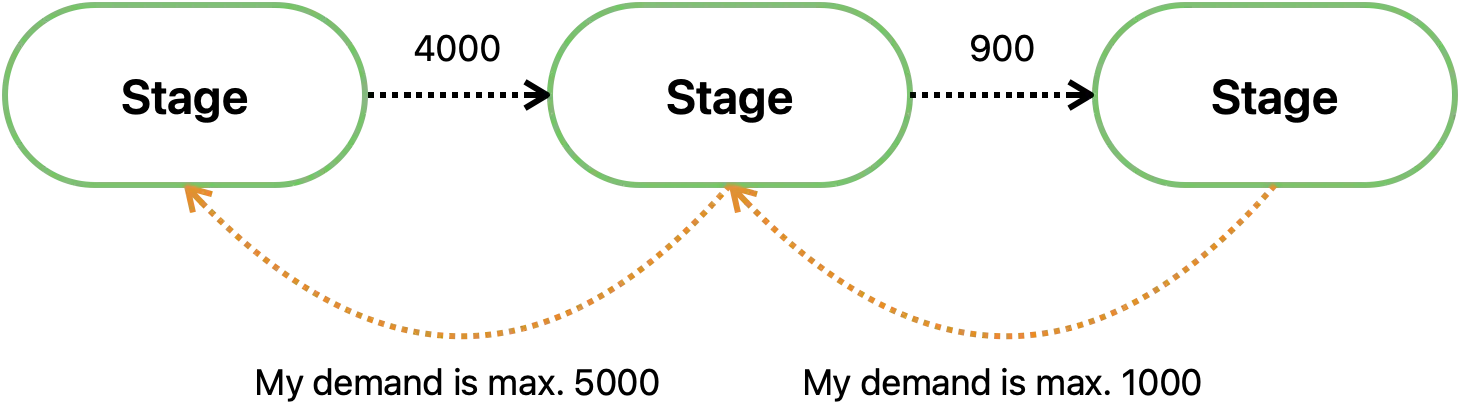
This is a self-regulating system, where any stage can become a bottleneck - by telling its predecessor “i’m done, send no more events”, the entire pipeline can grind to a halt after a while. This extreme case should naturally be avoided, and usually the stages will be arranged in such a way that matches demand with the supply from upstream.
GenStage handles the plumbing around arranging stages into coherent pipelines and getting the backpressure right. We as developers are expected to use following flavours of stages to build our data flow:
- Producers are the sources of events flowing downstream, basically a
fn produce() -> [Event]. - Producer-Consumers are intermediate stages which can both consume events and produce new ones. Think of them as
fn produceConsume(x: &[Event]) -> [Event]. - Consumers are the terminal stages which only consume events, so
fn consume(x: &[Event]).
As you can see, these abstractions basically differ only by their location within our pipeline directed acyclic graph (DAG). We’re now ready to design the layout of our SQS ingestion pipeline, and implement it next.
Pipeline Design
One of the use cases for GenStage is to consume data from third-party systems. The demand system with back-pressure guarantees we won’t import more data than we can effectively handle.
– José Valim in Announcing GenStage
Our design goal is simple: ingest messages from an SQS queue at a rate that does not exceed our capacity. The rate of consumption can be controlled by tweaking the number of messages per requests and sending concurrent requests. However - standard SQS queues ensure at-least-once message delivery, and no guarantee of message ordering. This implies that duplicate delivery is possible, and we should be prepared to handle it. Our design is sketches on the diagram below:
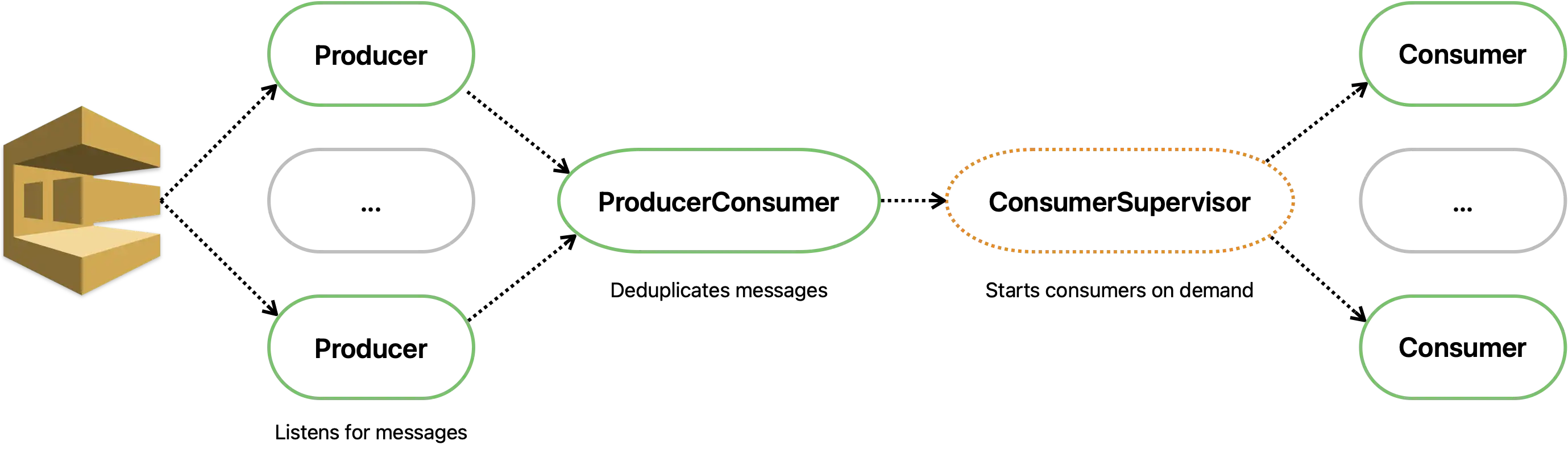
Allright, there’s some complexity that we didn’t cover yet. Let’s break it down:
- Producer calls SQS’s
receive_messageAPI on fixed intervals. If it receives no demand from the downstream, it will forgo that API call in the next tick. - ProducerConsumer receives messages from all linked producers and deduplicates them by keeping a
MapSetof most recent message IDs. - ConsumerSupervisor is an interesting part of
GenStagethat works much likeDynamicSupervisor, it will spin up at mostmax_demandconsumers which do the actual processing. - Consumers handle the message processing part and call SQS’s
delete_messageonce message has been processed.
Task behaviour rather that something more long-lived.Let us illustrate the actual implementation of this flow to better understand how backpressure and Elixir’s fault tolerance simplify our life.
Supervision Tree
This section will be quite long, nevertheless we’ll try to focus on the moving parts of the implementation. The full code will soon be available on our GitHub.
It’s always helpful to visualize the supervision tree to get a bird’s eye view of the system. We’ll then proceed from the bottom up, starting with the producer and ending with the topmost supervisor. This is our supervision tree:
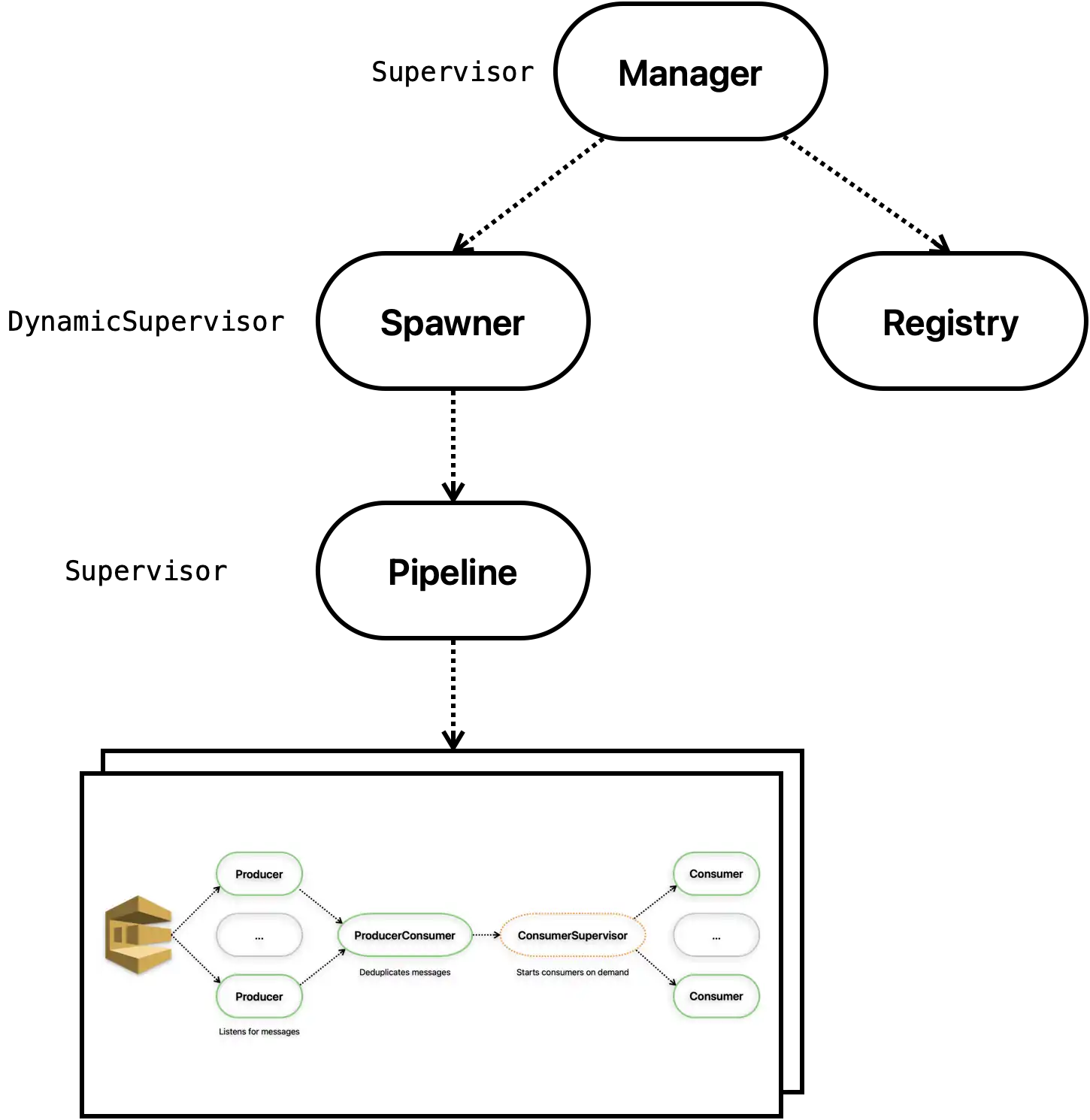
Okay, it’s not that complex, but it does show design choices characteristic for OTP applications:
- Top-level Manager is supervises the process registry shared among all pipelines, and the underlying Spawner dynamic supervisor.
- Registry is used to uniquely identify processes within the tree by some name. This allows us to have persistent references even across process restarts.
- Spawner is a dynamic supervisor that spawns individual pipelines for each SQS queue we want to monitor.
This supervision tree is self-contained and reusable, with some tweaks we could package it as a library. Chris Keathley explains why this is a good thing.
We begin by implementing our producer. Notice the use GenStage macro, which allows us to implement the handle_demand/2 callback. This is where GenStage tells us how many messages we can produce until the next such instruction. We query SQS for messages in handle_receive_messages, which is called either on demand or on a timer, but never both. We employ long polling to avoid needlessly hitting the SQS API when there’s nothing to fetch. Note that we’ll only do the fetching when demand > 0, and the fetching operation itself will decrement our locally stored demand counter.
The interesting part is also how we start our GenState here - via a Registry. A registry is a node-local key-value store useful for looking up processed by their names. This is exactly why we uniquely identify the producer GenStage by a via tuple, essentially a {source.id, index} pair. The ID is just some identifier for this particular SQS queue, and index a natural choice for the sequence of producers we start.
defmodule EventQueue.Producer do
@moduledoc """
Producer for Amazon SQS/SNS events
"""
use GenStage
alias AWS.Session
alias EventQueue.Message
alias EventQueue.Source
require Logger
@registry EventQueue.Registry
@receive_interval :timer.seconds(5)
def start_link([%Source{} = source, index]) do
GenStage.start_link(__MODULE__, source, name: via(source.id, index))
end
@impl true
def init(%Source{} = source) do
{:producer, %State{source: source}}
end
@impl true
def handle_demand(incoming_demand, %State{demand: demand} = state) do
handle_receive_messages(%State{state | demand: demand + incoming_demand})
end
@impl true
def handle_info(:receive_messages, %State{receive_timer: nil} = state) do
{:noreply, [], state}
end
@impl true
def handle_info(:receive_messages, %State{} = state) do
handle_receive_messages(%{state | receive_timer: nil})
end
def via(source_id, index) when is_integer(index) do
{:via, Registry, {@registry, {__MODULE__, source_id, index}}}
end
# Private
defp handle_receive_messages(%State{receive_timer: nil, demand: demand} = state) when demand > 0 do
messages = receive_messages(state, demand)
new_demand = demand - length(messages)
receive_timer = schedule_receive_messages(@receive_interval)
{:noreply, messages, %State{state | demand: new_demand, receive_timer: receive_timer}}
end
defp handle_receive_messages(%State{} = state) do
{:noreply, [], state}
end
defp receive_messages(%State{source: %Source{sqs_queue_url: queue_url} = source}, demand) do
{:ok, []}
end
defp schedule_receive_messages(interval) do
Process.send_after(self(), :receive_messages, interval)
end
end
This already takes care of the producer part. The next one the deduplicator, which implements the handle_events/3 callback to do its work. Note that cannot implement handle_demand/2 here, which is reserved for producers. In our toy example, we have a fixed range of producers identified by index of Source.consumers() e.g. 1..10. This allows us to conveniently subscribe our deduplicator to the producers in init/1 - notice the subscribe_to option that gets the list of via tuples referencing the producers.
The rest of the code is rather uneventful, we simply keep a cache of recently processed message IDs to filter out the duplicates:
defmodule EventQueue.Deduplicator do
@moduledoc """
Deduplicates SQS messages based on their IDs.
"""
use GenStage
alias EventQueue.Message
alias EventQueue.Producer
alias EventQueue.Source
@registry EventQueue.Registry
def start_link(%Source{} = source) do
GenStage.start_link(__MODULE__, source, name: via(source.id))
end
@impl true
def init(%Source{} = source) do
producers = for index <- Source.consumers(), do: {Producer.via(source.id, index), []}
{:producer_consumer, source, subscribe_to: producers}
end
@impl true
def handle_events(events, _from, %Source{} = source) do
{:noreply, filter_duplicates(events), source}
end
def via(source_id) do
{:via, Registry, {@registry, {__MODULE__, source_id}}}
end
# Private
defp filter_duplicates(messages) when is_list(messages) do
Enum.filter(messages, fn %Message{} = message ->
key = duplicate_key(message)
if Cache.exists?(key) do
Message.ack(message)
false
else
Cache.put(key, true, ttl: :timer.minutes(10))
true
end
end)
end
defp duplicate_key(%Message{id: id}) when is_binary(id), do: "sqs-msg-" <> id
end
Now comes the consumer manager, which is a ConsumerSupervisor that spawns consumers while respecing max_demand from the deduplicator. The main benefit of dynamic spawning is that end-consumers are often one-off tasks such as “insert this to DB”, and are best modelled as Task processes. In the init/1 callback we define define the child spec for the supervisor (note the transient strategy - we only want to restart if the consumer Task exists with an error, not when it finishes normally). Then we subscribe_to the deduplicator to receive messages from it:
defmodule EventQueue.ConsumerManager do
@moduledoc """
Manages the lifecycle of event consumers.
"""
use ConsumerSupervisor
alias EventQueue.Consumer
alias EventQueue.Deduplicator
alias EventQueue.Source
@registry EventQueue.Registry
def start_link(%Source{} = source) do
ConsumerSupervisor.start_link(__MODULE__, source, name: via(source.id))
end
@impl true
def init(%Source{} = source) do
children = [
%{
id: Consumer,
start: {Consumer, :start_link, []},
restart: :transient
}
]
opts = [
strategy: :one_for_one,
subscribe_to: [
{Deduplicator.via(source.id), []}
]
]
{:ok, children, opts}
end
# Private
defp via(source_id) do
{:via, Registry, {@registry, {__MODULE__, source_id}}}
end
end
This is concise, isn’t it? Just a supervised Task:
defmodule EventQueue.Consumer do
@moduledoc """
Consumes events from Amazon SQS/SNS.
"""
alias EventQueue.Message
def start_link(%Message{} = message) do
Task.start_link(fn ->
# Do something with the message
Message.ack(message)
end)
end
end
Spawning Pipelines on Demand
And now we need to bring all these moving parts under the umbrella of a supervisor. We need to instantiate the GenStage processes from left to right, so that successive components can safely subscribe_to their dependencies. We pass around our %Source{} struct which is kind of a blueprint for the pipeline, stating how many SQS consumers we want to start, and allowing us to uniquely namespace the process names by %Source{id: id}. The interesting part is the supervision strategy - :rest_for_one. This means “if a process fails, restart its sibling processes started after it”. The reason for this choice is found in GenStage documentation:
Producer terminates, all of the other processes will terminate too, since they are consuming events produced by it. In this scenario, the supervisor will see multiple processes shutting down at the same time, and conclude there are too many failures in a short interval.defmodule EventQueue.Pipeline do
@moduledoc """
A pipeline for consuming and processing events from Amazon SQS/SNS.
"""
use Supervisor
alias EventQueue.ConsumerManager
alias EventQueue.Deduplicator
alias EventQueue.Producer
alias EventQueue.Source
@registry EventQueue.Registry
def start_link(%Source{} = source) do
Supervisor.start_link(__MODULE__, source, name: via(source.id))
end
@impl true
def init(%Source{} = source) do
producers =
for index <- Source.consumers(),
do: Supervisor.child_spec({Producer, [source, index]}, id: "producer_#{source.id}_#{index}")
children =
producers ++
[
{Deduplicator, source},
{ConsumerManager, source}
]
Supervisor.init(children, strategy: :rest_for_one)
end
def via(source_id) do
{:via, Registry, {@registry, {__MODULE__, source_id}}}
end
end
The EventQueue.Pipeline supervisor can already spin up a self-contained pipeline for the provided %Source{}. To start a pipeline on demand, we propose writing a think DynamicSupervisor module that will do just that:
defmodule EventQueue.Spawner do
@moduledoc """
Dynamically spawns processing pipelines.
"""
use DynamicSupervisor
alias EventQueue.Pipeline
alias EventQueue.Source
@registry EventQueue.Registry
def start_link(_opts) do
DynamicSupervisor.start_link(__MODULE__, nil, name: __MODULE__)
end
@impl true
def init(_opts) do
DynamicSupervisor.init(strategy: :one_for_one)
end
@doc """
Starts a new pipeline with the given source, or errors out if it already exists.
"""
def start_pipeline(%Source{} = source) do
DynamicSupervisor.start_child(__MODULE__, {Pipeline, source})
end
end
And finally, we need a top-level supervisor that will manage our ubiquitous registry and the dynamic pipeline supervisor. This time, we employ the :one_for_one strategy, as there is no causal order in the children that requires us to restart all the siblings:
defmodule EventQueue.Manager do
@moduledoc """
Supervises the registry + pipeline manager.
"""
use Supervisor
alias EventQueue.PipelineManager
alias EventQueue.Source
require Logger
@registry EventQueue.Registry
def start_link(queues) do
Supervisor.start_link(__MODULE__, queues, name: __MODULE__)
end
@impl true
def init(queues) do
children = [
{Registry, keys: :unique, name: @registry},
{Spawner, []}
]
Supervisor.init(children, strategy: :one_for_one)
end
defdelegate start_pipeline(source), to: Spawner
end
Summary
GenStage is a useful abstraction for reasoning about data flows, and building pipelines that process data in stages. Out of the box, we get backpressure, interfaces for passing around events and distributed processing. More importantly, we can reason about the flow of data, identify bottlenecks and eliminate them.
You should also take a look at Broadway and Flow, both libraries tackle parallel processing and are built on top of GenStage. In fact, Broadway has an SQS producer which served as an inspiration for our EventQueue.Producer.
Sources:
- GenStage documentation
- Concurrent Data Processing in Elixir by Svilen Gospodinov. Great book overall for mastering OTP.


{kind=link}